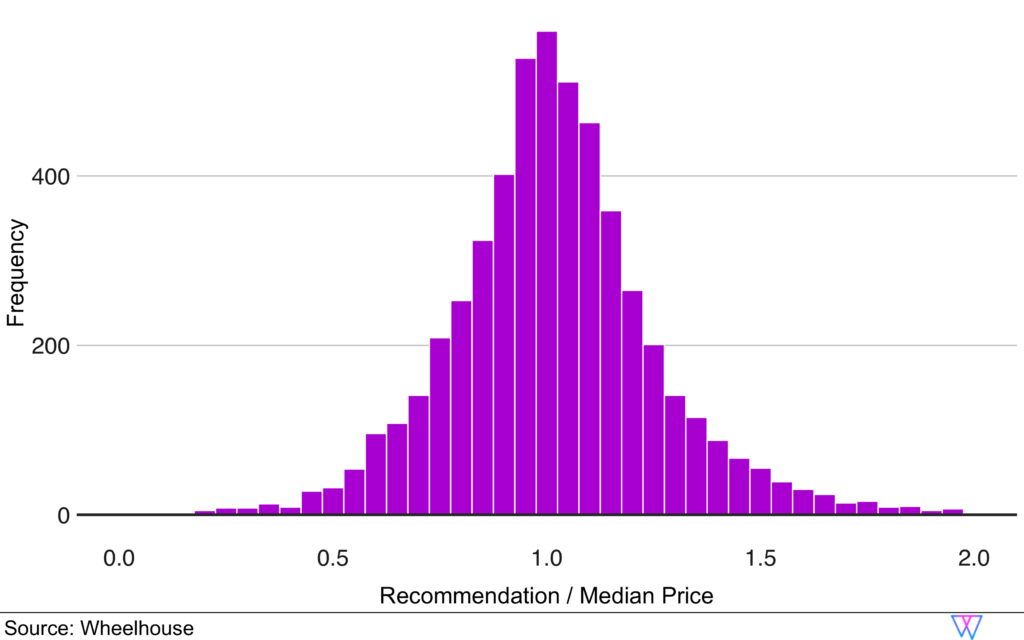
Wheelhouse’s Base Price Model (Pt 2)
March 30, 2021 | Andreas Buschermohle
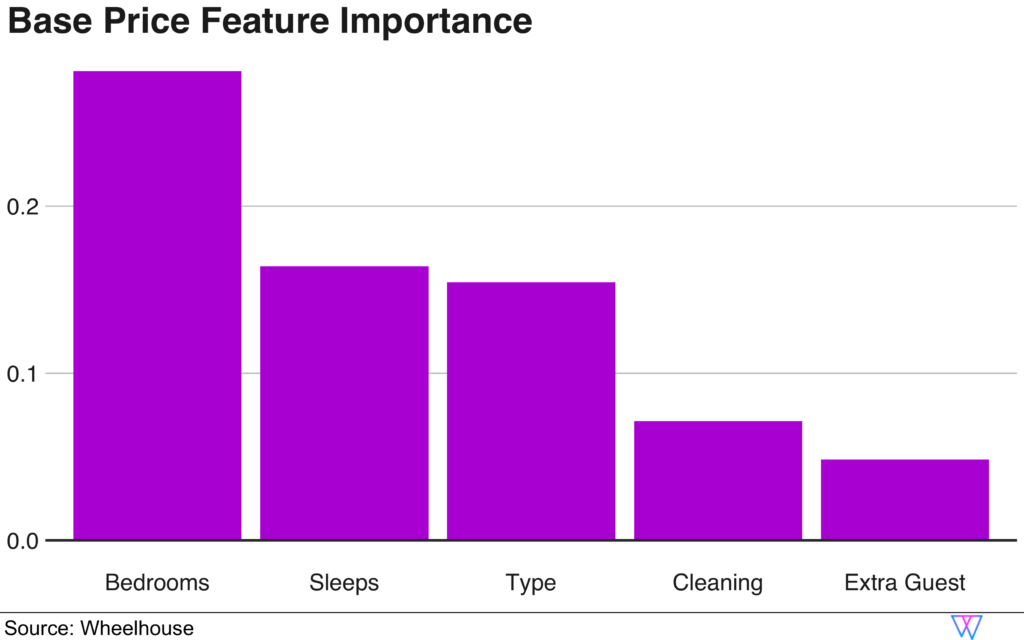
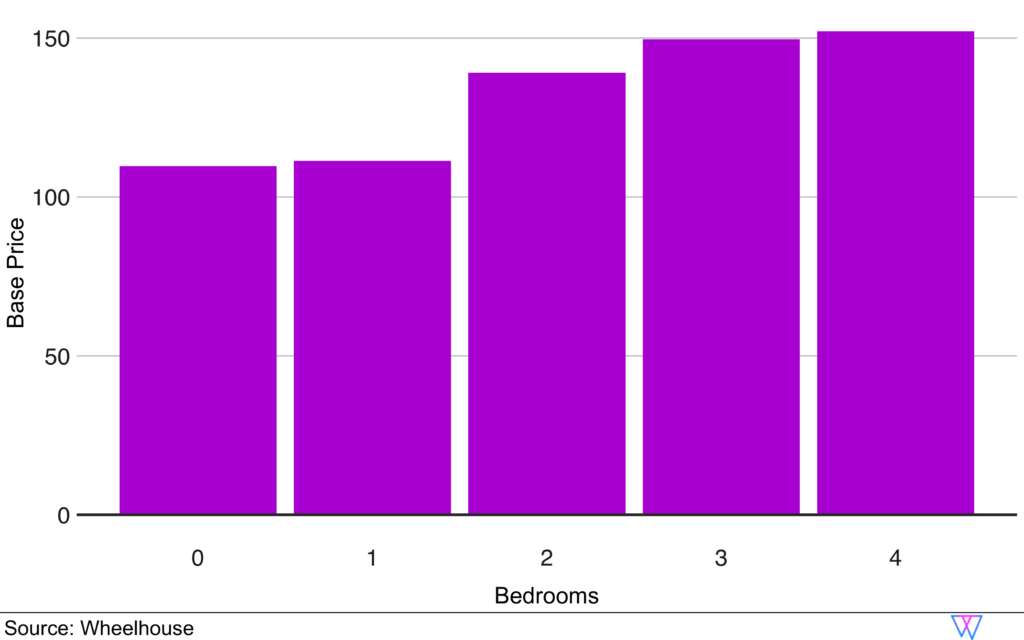
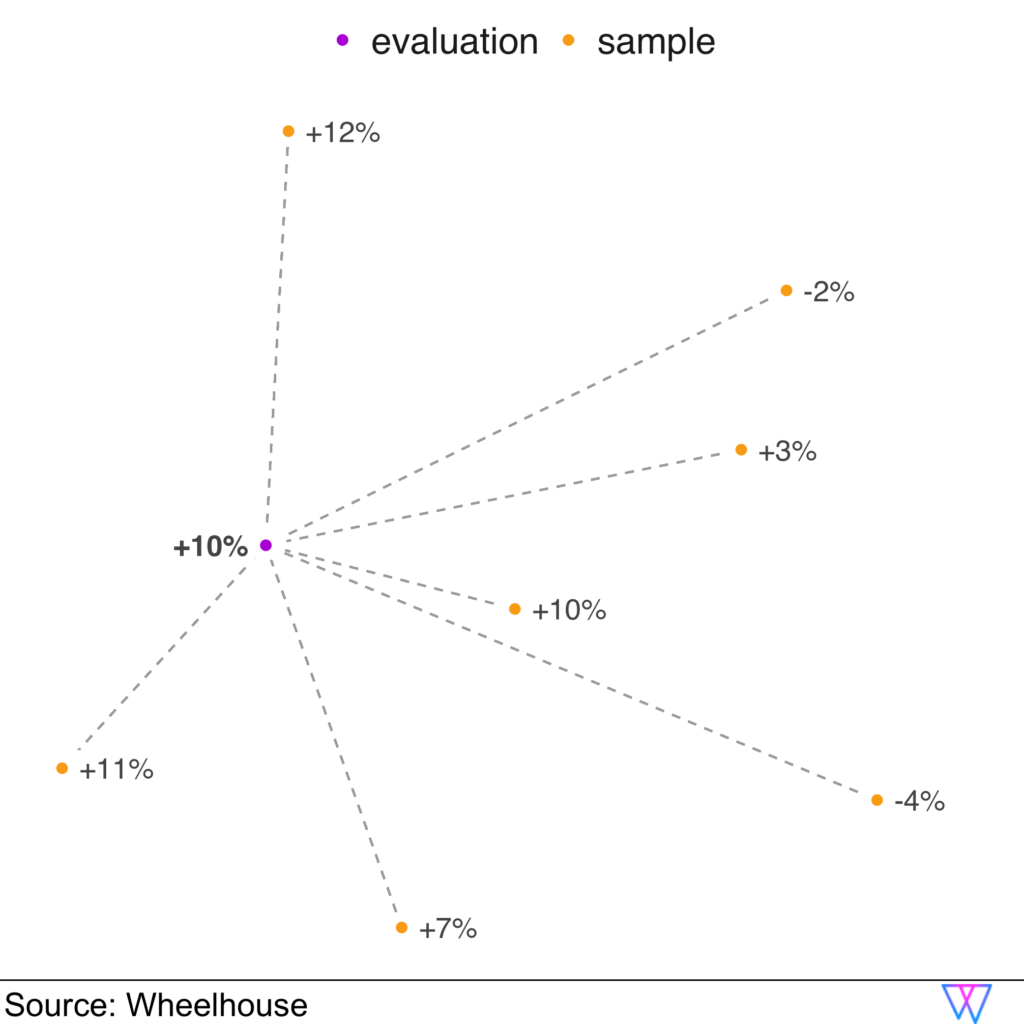
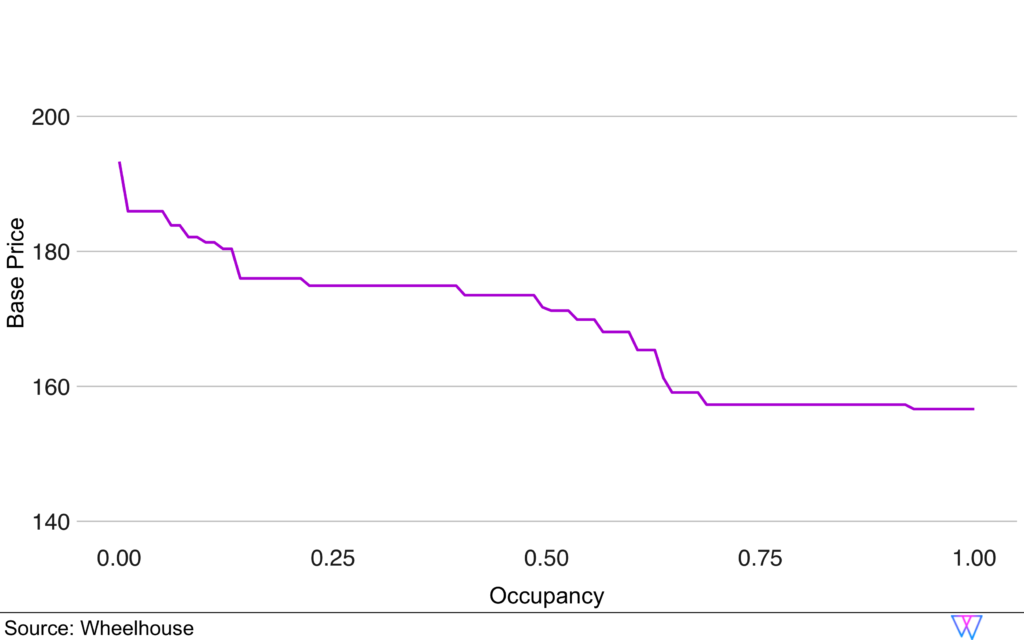
Share



Blog search
Recent posts
-
Wheelhouse Presents: Ratestrology
April 1, 2023 | BY Andrew Kitchell
-

Short-Term Rental Agreement: What to Include & Free Templates
January 17, 2023 | BY Hailey Friedman
-

Hostfully Review: Vacation Rental Management Software [2023]
January 14, 2023 | BY Hailey Friedman
-

Escapia Software Review [2023]
January 6, 2023 | BY Hailey Friedman




