How we measure our Pricing Engine: Methodology Write-Up
June 9, 2021 | Andrew Kitchell
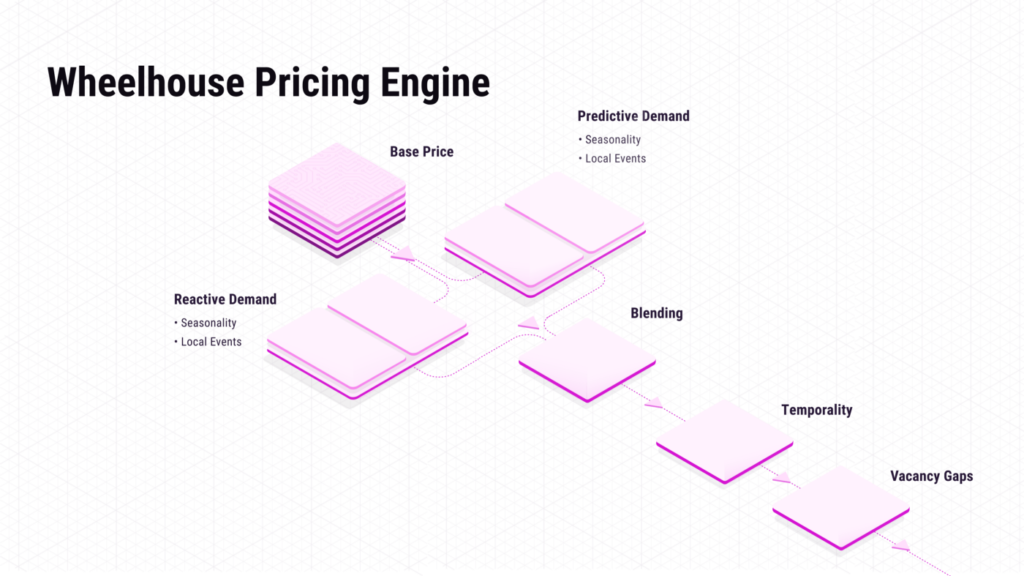
Detailing the 3 methodologies we designed with HomeAway, TripAdvisor & other teams to measure the Wheelhouse model
Intro
When we started building Wheelhouse, we were predicated on a few core beliefs:
- Pricing is the ultimate source of truth
- The methods you develop to measure the model are as important as the model itself
Additionally, it’s critical, in our opinion, for pricing engines to share HOW they work, so as to enable hosts & owner to better manage their pricing engine.
To this day, we are still the only pricing engine in the short-term rental space that has:
- Published our research & statistical approaches that power our Pricing Engine
- Developed & audited our Pricing Engine with 3rd party teams
- (As of today) published how we measure our Pricing Engine's performance
"Solving" an impossible problem
Here is a secret about short-term rental Pricing Engines:
In truth, there is no 100% perfect method to measure the performance of a pricing engine for Short-term rentals.
Why is this?
It’s because on individual listings, you can never run a perfectly controlled pricing experiment, which would be that a listing would both use & not use a pricing engine… at the same time.
However, thanks to a huge number of A/B tests, as well as the following methodologies Wheelhouse developed with external data science teams, we have developed methodologies that when combined, illustrate the effectiveness of the Wheelhouse Pricing Engine.
Below is the write-up we developed for the leadership teams of our external partner, to explain more about how we “solve” this impossible problem.
While this paper will become slightly more technical, the 3 key methodologies we use to measure your pricing engine include:
- CompSet Method: How does each listing perform against a CompSet, both before & after using pricing
- Historical Method: How does each listing perform against their prior booking history, before & after using pricing
- Hypothetical Method: How much did Wheelhouse predict each listing would earn, and how much did it actually earn
When combined, these 3 methodologies (and the underlying data that double-checks their work) allows us to share that Wheelhouse earns the average listing 22.6% more revenue.
While it is not possible to cite a 100% precise figure, these 3 methods at least enable us to (a) know we make a significant impact on revenue, and (b) that we are highly accurate at projecting revenue.
Our Methodologies - Deeper Dive
The intro we prepare for our evaluation partners
Dynamic pricing can meaningfully impact many metrics of a marketplace, including click-through rates, inquiry rates, and the probability of getting a booking.
To measure total revenue, there are three methodologies that should be considered. Combined, they will give a clear understanding of the true impact of dynamic pricing!
Ideally, we could measure the impact of dynamic pricing by studying the same listing, for the same time period (hence, the same market conditions), once using a simple pricing strategy, and once using dynamic pricing strategy.
Since this is essentially impossible, our methodologies aim at compensating for factors that might impact our measurements, for better or worse, and alter our understanding of the impact of dynamic pricing.
Methodology #1: Control Group/CompSet Comparison
The Control Group Comparison measures a set of dynamically-priced listings against a set of simply-priced listings.
The strength of this methodology is that it evaluates the performance of the two listing groups that are experiencing the same market conditions (seasonality, events, weather, etc).
The weakness of this methodology is that it can be susceptible to performance differences that occur due to factors we have not appropriately weighted.
However, by carefully selecting control groups, we can reduce the impact of these factors.
Setup
To set up this test correctly, we recommend generating control groups of >20 simply-priced listings for each dynamically-priced listing.
These control groups should be comprised of similar nearby listings.
We define “similar” as listings that have the same number of bedrooms, and a similar number of bathrooms (+/-1) and sleeps (+/- 2). We define “nearby” as listings that are within 1km to 5km, depending on the density of listings in the market.
With our control group established, we next measure the difference between the dynamically priced listing and each individual listing in the control group. We do this by using our base price model, which assesses the relative importance of various features or amenities.
Additionally, it’s important to control for differences in the search ranking of each listing, and for availability rates across the considered time period. To do this, we consider all performance measures (CTR, inquiries, bookings, and revenue) relative to the number of available days, and consider the impact of search rankings on each listing.
By comparing the performance of dynamically priced listing to the weighted performance of the listings in its control group, we can isolate the performance differential due to dynamic pricing. And, by analyzing multiple control groups, we can verify a statistically significant change. This analysis can be performed on a month-to-month basis to analyze the impact of dynamic pricing over time.
Validation Tests
Two tests can validate whether our methodology is working as expected.
First, we select a simply-priced listing randomly from the market, instead of our dynamically priced inventory. As described above, we select a corresponding simply-priced control group for each simply-priced listing.
Because both the target listing and the control group are simply-priced, we expect the comparison results to show no significant difference. If the results do show a significant difference, we know that our control groups are not accurately selected and should be adjusted.
Second, we select two sets of obviously different listings, (i.e. studios and 3 bedroom listings).
We use one group of listings as a replacement for the investigated group, and the other as a replacement for the control group. Again, we compare the results of these differing sets.
Because the two sets are very different, we expect to see significant differences in their performance. This is because two different inventory types should perform differently, at least with respect to revenue.
If we cannot detect a significant change, our methodology has compensated for too many factors, and we need to reduce the complexity of our methodology.
With these validation strategies, we can discern which features we should use for selecting the control group, and which sources of error need to be considered.
Data Considered
- Basic properties of all listings: bedrooms, bathrooms, sleeps, room-type, amenities, photos, additional fees
- Prices of all listings throughout the considered time period: price, stay date, any audit trail of changes
- Availability of all listings throughout the considered time period: availability, stay date, any audit trail of changes
- Bookings for all listings in a market throughout the considered time period: listing, time of booking, booked price (ideally by day), fees and taxes, stay dates, number of guests
- Inquiries for all listings in a market throughout the considered time period: listing, time of inquiry, stay dates, number of guests (When possible)
- Search ranking of all listings throughout the considered time period: ranking, search day (When possible)
- Booking performance timing of you/your competition’s bookings
Methodology #2: Historical Comparison
The Historical Comparison is designed to measure the performance of individual listings before & after introducing dynamic pricing.
The strength of this methodology is that it is not affected by random differences between listings that might impact the results of the Control Group comparison.
The weakness of this methodology is that it can be susceptible to seasonality, long-term changes in market conditions, or changes within the listing itself (such as improvements to a home or negative reviews).
Setup
Due to constantly changing market conditions, historical performance can not be immediately compared to current performance.
For example, while it may seem ideal to compare the monthly performance of listings year-over-year, changing market conditions (or major local events) can dramatically impact the performance of listings (or an entire marketplace) year-over-year.
Therefore, we need an approach that enables us to compare different times periods (i.e July 2015 to December 2015) by striping away performance changes that are due to changing market conditions.
In order to do this, we compare time periods in question against the all-time average performance of a marketplace. For example, let’s assume the average historical occupancy rate for a market is 50%. For the time period in question, statically priced inventory has an average occupancy rate of 42% and dynamically priced inventory has an occupancy of 56%. By knowing the average market performance, we are able to gain more context into the true impact of dynamic pricing.
After correcting the historical performance for changing market conditions, we next are able to analyze individuals listings to see if unique events (such as a host adding a new bedroom) have resulted in a listing having a significant performance change in the past.
When pronounced changes in historical performance are detected at listings, we can adjust our measurement of these listings to further isolate the impact of dynamic pricing.
Additionally, since newly created listings might have incomplete information (i.e. a host has not had time to add photos) it is advisable to discount or disregard the first three months of performance data for a listing.
Validation Tests
Similarly to the Control Group validation, two tests can validate whether our historical methodology is accurate.
First, for any time period in question, we measure simply-priced listings that have not changed their pricing, and analyze their historical performance versus their current performance. In this case, we expect that the current and historical performance should be similar, as the pricing has not changed and, due to the methods we describe above, we can correct our measurements so they are not impacted by changing market conditions.
If major differences are found, we know that we did not take into account all changes in market conditions that could have impacted our performance measurement, and thus we have to adjust our methodology.
The second validation considers the performance of dissimilar listings (1BR/4BR, or listings in very different neighborhoods). In this case, we expect that the current and historical performance should be dissimilar, as we expect that these unique inventory groups would perform differently.
If the performance results for these two distinct groups do not differ significantly, we know that our methodology is compensating for factors that are important for measuring performance differences.
As in the previous methodology, we are able to use our validation tests to inform the complexity of our measurement approach and to select the relevant influences.
Data Considered
- Basic properties of all listings: bedrooms, bathrooms, sleeps, room-type, amenities, photos, additional fees
- Prices of all listings throughout the considered time period: price, stay date, any audit trail of changes
- Availability of all listings throughout the considered time period: availability, stay date, any audit trail of changes
- Bookings for all listings in a market throughout the considered time period: listing, time of booking, booked price (ideally by day), fees and taxes, stay dates, number of guests
- Booking performance timing of you/your competition’s bookings
Methodology #3: Hypothetical Comparison
Our final methodology considers a “what if” scenario.
In this approach, we compare observed revenue for a dynamically priced listing to what we believe this listing would have earned had it kept its prior pricing strategy in place.
Our team has spent considerable time assessing whether our model can accurately predict – on aggregate – the booking performance of each unit given its current pricing. These calibration metrics show good-to-excellent performance across all markets.
As discussed in our intro, it is not possible to observe a listing’s performance under its previous pricing once dynamic-pricing is turned on. By using our predictive model, we can infer what the expected amount of bookings and revenue would have been over this period had the listing retained its prior prices.
The strength of this methodology is that it allows us to compare a listing’s performance under the same market conditions. Therefore, random factors that affect the Control Group Comparison and Historical Comparison do not affect this methodology.
The weakness of this approach is that it relies on the booking model to correctly predict the booking probability for different pricing strategies, and thus is based on parts of the same model that produces our pricing recommendations.
Setup
This approach relies on our market-wide booking model, which infers the booking probability for each listing, for each night, at it’s original price.
With this, we compare observed revenue to the model-implied expected revenue. In this case, we define “expected revenue” as the product of the daily booking probability (as inferred from the booking model) and the original price for which the listing was offered.
Once observed and expected revenue for each day in the study period are calculated, we can assess the performance of the dynamic pricing approach using mean squared error. We can then compare the complete cohort of dynamically priced listings to its hypothetical simply priced performance.
Validation
To validate this approach, we need to know that our booking model correctly predicts booking probabilities at different price points.
We do this on an aggregate level by using our forecasting/backtesting system to compare the number of bookings we see on a given day at a specific price point to the number of bookings our model predicted.
Data Considered
- Basic properties of all listings: bedrooms, bathrooms, sleeps, room-type, amenities, photos, additional fees
- Prices of all listings throughout the considered time period: price, stay date, any audit trail of changes
- Availability of all listings throughout the considered time period: availability, stay date, any audit trail of changes
- Bookings for all listings in a market throughout the considered time period: listing, time of booking, booked price (ideally by day), fees and taxes, stay dates, number of guests
- Booking performance timing of you/your competition’s bookings
Conclusion
While we know that no single listing can be simply-priced and dynamically-priced on the same day, these methodologies can serve as proxies for determining the impact of dynamic pricing on a given marketplace.
And, while each methodology is affected by a set of possible errors, by utilizing three different methodologies, a robust comparison is possible and reliable results can be produced.



Blog search
Recent posts
-
Wheelhouse Presents: Ratestrology
April 1, 2023 | BY Andrew Kitchell
-

Short-Term Rental Agreement: What to Include & Free Templates
January 17, 2023 | BY Hailey Friedman
-

Hostfully Review: Vacation Rental Management Software [2023]
January 14, 2023 | BY Hailey Friedman
-

Escapia Software Review [2023]
January 6, 2023 | BY Hailey Friedman




